Методика автоматического сбора смысловых облаков: как заставить ИИ использовать скрытые ключи конкурентов без переспама
Написать текст нейросетью онлайн сегодня умеет любой. Проблема не в генерации — а в том, что 90% ИИ-статей не попадают в топ, потому что в них нет скрытой семантики, которую Яндекс считывает с конкурентов. Решение — сначала парсить выдачу, выгружать LSI-фразы из топ-30, и только потом запускать нейросеть с этим контекстом внутри промпта.
В этой статье разберем: почему классические ТЗ провалились, как устроен парсинг SERP, каким образом ТекстЗавод автоматизирует этот процесс за 2 минуты, как строить промпты для органичного внедрения ключей и как проверить, что текст попал в интент.
Почему классические ТЗ на копирайтинг больше не работают

Ситуация стандартная: SEO-специалист отдает копирайтеру бриф с 10 ключами из Wordstat, тот пишет текст с вхождениями — и страница зависает на 15-й позиции. Не потому что текст плохой. Потому что Яндекс давно перешел на векторную модель ранжирования, где простое вхождение ключа — лишь один из десятков сигналов.
Яндекс оценивает семантическую близость страницы к запросу через матрицы плотности понятий. Это значит: если конкуренты в топ-5 упоминают «коммерческий интент», «намерение пользователя» и «поведенческий фактор» в одном смысловом кластере — а ваша страница нет — алгоритм считает её менее релевантной, даже при одинаковом ссылочном весе.
Анализ 100+ ниш показывает устойчивую закономерность: статьи с плотным семантическим облаком (LSI-фразы + синонимичные конструкции) ранжируются в среднем на 40% выше при сопоставимом ссылочном профиле. Это не магия — это математика: больше пересечений с эталонными страницами топа, выше косинусное сходство векторов.
Проблема копирайтеров в другом. Wordstat показывает прямые запросы. Но 70% смысловых сущностей, которые Яндекс ищет на странице, в Wordstat вообще не видны — они рассеяны по текстам конкурентов, заголовкам, подзаголовкам и FAQ-блокам. Копирайтер их не видит. Он пишет по брифу — и пропускает именно те слова, которых не хватает для попадания в топ.
Стандартное ТЗ строится на экспертизе SEO-специалиста: он сам решает, какие LSI-фразы важны. Это субъективно и медленно. При потоке в 30-50 статей в месяц — это потраченные ресурсы впустую. Выход один: делегировать сбор семантики алгоритмам, которые не устают и не пропускают слова.
Алгоритм парсинга SERP — что именно брать у конкурентов

Парсинг выдачи — это не просто скачать тексты топ-10. Это структурированный сбор данных, из которого потом строится семантическое облако. Вот что реально влияет на результат.
Заголовочные структуры H1-H6 как карта интента
Первое, что нужно забрать у конкурентов, — заголовки. H1 показывает главный угол страницы. H2 и H3 раскрывают подтемы, которые пользователь ожидает найти в ответ на свой запрос. Совокупность заголовков топ-10 дает 100% покрытие интента: вы видите, что именно Яндекс считает полным ответом на запрос.
На практике это выглядит так: берете запрос, снимаете топ-10, выгружаете все заголовки в таблицу, группируете повторяющиеся темы. Если 7 из 10 конкурентов используют блок «Как выбрать…» — этот блок обязателен в вашей статье. Если только 2 — можно пропустить.
Заголовки также выдают коммерческий интент: слова «цена», «купить», «сравнение», «отзывы» в H2 прямо говорят, что страница должна отвечать на транзакционный запрос, а не информационный.
Текстовый корпус конкурентов — база для семантического анализа
После заголовков — полный текст. Его нужно очистить от шума: убрать навигационное меню, футер, рекламные блоки, виджеты. Остается только смысловое тело страницы. Именно из него извлекаются LSI-фразы.
Технически это делается через Python-скрипты с библиотеками BeautifulSoup и lxml. Скрипт обходит топ-30, парсит теги <p>, <h1>–<h6>, <li>, складывает в единый текстовый корпус. Дальше — TF-IDF или word2vec по этому корпусу, чтобы выделить слова с высокой информационной ценностью.
Альтернатива — готовые модули типа того, что встроен в ТекстЗавод. Там парсинг топ-30 Яндекса занимает меньше двух минут: платформа сама обходит выдачу, очищает данные и формирует список пересекающихся сущностей — тех слов и фраз, которые встречаются у большинства конкурентов одновременно.
Фильтрация шума — почему чистота корпуса важна
Если не убрать меню, футеры и рекламные блоки — в семантическое облако попадет мусор. «Контакты», «Главная», «Политика конфиденциальности» будут весить наравне с реальными LSI-фразами. Результат — засоренный список, из которого нейросеть будет брать нерелевантные слова.
Фильтрация строится в два этапа. Первый — технический: удаление по CSS-классам (.nav, .footer, .sidebar). Второй — семантический: стоп-слова, слишком короткие токены (менее 3 символов), слова с частотностью ниже порога по корпусу. После этого остается чистый список — от 50 до 200 LSI-фраз в зависимости от ниши.
Вот типичный пример разницы до и после фильтрации для запроса «написать текст через ии»:
| Без фильтрации | После фильтрации |
|---|---|
| главная, контакты, меню | семантическое облако, интент пользователя |
| подписаться, поделиться | плотность ключей, LSI-копирайтинг |
| политика конфиденциальности | релевантность страницы, векторная модель |
| copyright, все права защищены | парсинг топ-30, структура заголовков |
| загрузить, скачать PDF | коммерческий запрос, поведенческий сигнал |
Разница очевидна. Чистый корпус дает чистый список — и нейросеть работает с ним корректно.
Как ТекстЗавод автоматизирует SERP-анализ за 2 минуты

Вручную всё вышеописанное занимает 2-4 часа на одну статью. Для потока в 30 материалов в месяц — это 60-120 часов только на подготовку семантики. Ни один SEO-специалист агентства не потянет такой объем без делегирования алгоритмам.
ТекстЗавод закрывает этот цикл автоматически. Специалист вводит запрос — платформа сканирует топ-30 Яндекса, извлекает заголовочные структуры и текстовые тела страниц, фильтрует шум и формирует список пересекающихся сущностей. Всё это — за 2 минуты без единой строки кода.
Если хотите проверить — запустите бесплатный SERP-анализ прямо сейчас. По промокоду «Завод03» получите три статьи в подарок за регистрацию.
Модуль парсинга — как работает под капотом
Сервис обходит выдачу Яндекса по целевому запросу, снимает позиции 1-30 (не только топ-10, как большинство аналогов). Это принципиально: позиции 11-30 часто содержат альтернативные углы и редкие LSI-фразы, которые топ-10 игнорирует. Расширенный охват дает семантическое облако на 20-30% плотнее.
После парсинга — алгоритм пересечений: платформа отбирает слова и фразы, которые встречаются хотя бы у трети конкурентов. Это и есть скрытая семантика запроса — то, что Яндекс ожидает увидеть на странице, претендующей на топ.
Параллельно система анализирует заголовочные структуры и строит шаблон контентной архитектуры: какие H2-блоки обязательны, какие — опциональны, где конкуренты используют таблицы и списки. SEO-специалист получает не просто список слов, а готовую структуру будущей статьи.
Двойной прогон через Gemini — структура плюс интеграция ключей
Генерация статьи в ТекстЗаводе разбита на два этапа. Первый — Gemini строит скелет: заголовки, подзаголовки, порядок блоков. Это делается на основе структурного анализа конкурентов — так архитектура текста уже соответствует ожиданиям поисковика.
Второй этап — интеграция LSI-фраз в готовую структуру. Нейросеть получает промпт с явным списком слов, которые нужно распределить по тексту органично, без переспама. Плотность каждого ключа контролируется алгоритмически — главный запрос не превышает 1.5%, LSI-фразы встраиваются контекстно.
Результат — статья от 1 000 до 20 000 знаков, в которой семантическое облако конкурентов присутствует не как механическое вхождение, а как смысловой слой. Яндекс это видит. Именно поэтому такие тексты ранжируются иначе, чем написанные по стандартным ТЗ.
Промпт-инжиниринг для естественного внедрения ключей

Сырой список LSI-фраз — ещё не результат. Главный вопрос: как дать его нейросети так, чтобы она встроила слова органично, а не набила ими каждый абзац?
Ответ — в архитектуре промпта. Нейросеть ии чат написать текст умеет хорошо, но без четких инструкций по распределению ключей она либо игнорирует их, либо переспамит. Нужна явная логика.
Запрет на прямое вхождение в каждом абзаце
Первое правило промпта — ограничение частоты. Если в тексте на 5 000 знаков ключевая фраза встречается 10+ раз — это прямой путь к фильтру Баден-Баден от Яндекса. Порог безопасности — не выше 1.5% для главного ключа.
В промпте это формулируется явно: «Каждый ключ из списка используй не чаще одного раза на 2-3 абзаца. Главный запрос — не чаще 3 раз на весь текст». Нейросеть принимает это как ограничение и работает в рамках.
Дополнительно — инструкция заменять повторы местоимениями. Вместо того чтобы писать «написать текст с помощью GPT» четыре раза — один раз полностью, дальше «этот подход», «такой формат», «данный метод». Это снижает механическую плотность без потери смысла.

Роль SEO-редактора в промпте — зачем она нужна
Нейросеть без контекста генерирует усредненный текст. Когда вы даете ей роль — результат меняется. Конструкция «Ты — SEO-редактор с опытом работы в Рунете. Пиши так, чтобы текст прошел антиплагиат и не выглядел машинным» — смещает вероятностное распределение токенов в сторону более живых конструкций.
Проверено на практике: тот же промпт с ролью и без дает разные результаты по оценке Тургенева. С ролью — показатель воды в среднем на 2-3 единицы ниже. Без роли — стандартные ИИ-конструкции, которые детекторы ловят с вероятностью 70%+.
Роль задает не только стиль, но и логику расстановки ключей. Редактор думает о читателе — и нейросеть начинает имитировать эту логику: ключи появляются там, где они уместны по смыслу, а не где алгоритм посчитал нужным.
Инструкция по закрытию болей конкурентов
Самый сильный прием — дать нейросети не просто список LSI-фраз, а связку: «эта фраза закрывает вот такую боль пользователя». Формулировка в промпте: «Распредели ключевые слова по тексту так, чтобы каждое появлялось в контексте решения конкретной проблемы из анализа конкурентов».
Это переключает нейросеть с механического вставления слов на смысловое встраивание. Слово «релевантность страницы» появится не в случайном предложении, а рядом с объяснением, почему страница должна отвечать на интент — и это логично.
Пример структуры промпта для попросить нейросеть написать текст с LSI-интеграцией:
Роль: SEO-редактор, пишущий для Рунета.
Задача: Написать статью на [тему] объемом [N] знаков.
Структура: [H1, H2, H3 из анализа конкурентов]
LSI-список: [50-200 фраз из парсинга]
Ограничения:
- Главный ключ — не чаще 3 раз
- Каждая LSI-фраза — 1-2 раза, контекстно
- Никаких списков из 10+ пунктов без пояснений
- Абзацы — не более 5 предложений
Интент: [информационный / коммерческий / навигационный]
Этот шаблон — не магия. Это логические расчеты, переведенные в язык инструкций для модели. ТекстЗавод генерирует подобный промпт автоматически на основе результатов SERP-анализа — специалисту не нужно собирать его вручную каждый раз.
SEO-продвижение через контент — почему это работает лучше рекламы

Когда речь заходит о привлечении клиентов на сайт, обычно рассматривают три канала: платная реклама в Яндекс.Директе, таргетированная реклама в социальных сетях и SEO-продвижение через контент. Первые два дают трафик сразу — и обрезают его ровно в момент, когда заканчивается бюджет.
SEO-статья работает иначе. Попав в топ-3 Яндекса по целевому запросу, страница приводит трафик месяцами без дополнительных расходов. Бюджет потрачен один раз — на создание и оптимизацию материала — а результат накапливается со временем. Это принципиально другая экономика по сравнению с Директом, где каждый клик стоит денег.
Есть ещё один аргумент в пользу контента — качество аудитории. Человек, который сам нашел статью в поиске, прочитал её и убедился в экспертизе, приходит к покупке уже подготовленным. Его не прерывали баннером. Он сам сделал выбор изучить тему — и ваш материал оказался рядом в нужный момент.
GEO-оптимизация — ниша, которая пока почти пуста
Отдельное направление — продвижение в нейровыдаче. Яндекс Алиса, Google AI Overview и ChatGPT всё чаще отвечают на запросы пользователей напрямую, цитируя конкретные страницы. Это называют GEO-оптимизацией (Generative Engine Optimization) — адаптация контента под то, чтобы нейросеть выбрала именно вашу страницу как источник.
Конкуренция в этом сегменте пока минимальна. Большинство сайтов ещё не думают о том, как попасть в ответы ИИ-ассистентов. Это значит: зайти в нейровыдачу сейчас — значит занять позицию раньше конкурентов, пока стоимость входа низкая.
Статьи, оптимизированные под GEO, строятся по chunk-принципу: каждый блок самодостаточен и понятен без контекста остальной страницы. Именно такой формат нейросети цитируют чаще всего. И именно такой формат генерирует ТекстЗавод — платформа анализирует структуру топ выдачи, строит контент-план и создает готовые тексты, адаптированные одновременно под классический поиск и под нейроблоки.
Попробуйте ТекстЗавод прямо сейчас. Промокод «Завод03» — три статьи бесплатно после регистрации.
Проверка релевантности — как понять, что текст попал в интент

Текст написан. Ключи распределены. Но попал ли он в интент — это отдельный вопрос. Три метрики, которые дают ответ.
Векторное сравнение с эталонными страницами
Самый технологичный способ — сравнить косинусное сходство вектора сгенерированной статьи с векторами страниц из топ-5. Для этого используют sentence-transformers или аналогичные библиотеки: тексты переводятся в числовые представления, и алгоритм считает угол между ними.
Порог нормы — косинусное сходство выше 0.75 с медианным значением по топ-5. Если ниже — текст семантически далек от того, что Яндекс считает релевантным ответом. Это значит: либо не хватает LSI-фраз, либо структура не совпадает с ожиданиями по интенту.
На практике этот шаг часто пропускают — он требует технической экспертизы. Но понимать принцип важно: Яндекс делает ровно то же самое, только на своих серверах, и именно этот расчет влияет на позицию страницы.

Контроль уникальности через text.ru
Для коммерческих текстов в 2026 году норма уникальности по text.ru — 90% и выше. Ниже этого порога — риск санкций или просто неранжирование. ИИ-генерация без постобработки часто дает 70-80%, потому что модели воспроизводят популярные конструкции из обучающих данных.
ТекстЗавод прогоняет каждую статью через text.ru автоматически. Если уникальность ниже порога — система флагирует материал для доработки. Это встроено в рабочий процесс, а не вынесено на ручной контроль специалиста.
Отдельно — проверка на AI-детекцию. Тот же text.ru умеет определять машинное происхождение текста. Норма для безопасного размещения — менее 20% вероятности ИИ-генерации по шкале детектора. Двойной прогон через Gemini с ролевым промптом обычно дает результат в диапазоне 15-25% — на границе нормы. Постредактирование человеком снижает показатель до 5-10%.
Показатель воды по Тургеневу — финальный фильтр
«Тургенев» — сервис Ашманова для анализа информационной насыщенности текста. Показатель выше 7 единиц означает, что в тексте слишком много вводных конструкций, пустых прилагательных и риторических оборотов. Яндекс учитывает этот сигнал при оценке качества страницы.
Норма для SEO-текстов — не выше 5-7 единиц. ИИ-генерация без настройки часто дает 8-12, потому что модели склонны к избыточным связкам и вводным фразам. Хорошо настроенный промпт с явным запретом на «воду» снижает показатель до 4-6 уже на этапе генерации.
Таблица контрольных метрик перед публикацией:
| Метрика | Инструмент | Норма 2026 |
|---|---|---|
| Уникальность | text.ru | 90%+ |
| AI-детекция | text.ru Neurotools | менее 20% |
| Водность | Тургенев | до 7 единиц |
| Академическая тошнота | Advego | до 9% |
| Плотность главного ключа | Advego | 1-2% |
| Косинусное сходство с топ-5 | sentence-transformers | от 0.75 |
Часто задаваемые вопросы

Можно ли попросить нейросеть написать текст сразу с LSI-фразами без предварительного парсинга?
Технически — да, но результат будет слабее. Без парсинга нейросеть опирается только на свои обучающие данные, которые не отражают актуальную выдачу Яндекса по конкретному запросу. Конкуренты в топе используют термины и конструкции, которых нет в стандартных обучающих наборах. Парсинг SERP — это способ передать нейросети актуальный контекст, а не полагаться на усредненные знания модели.
Сколько LSI-фраз нужно давать нейросети в одном промпте?
Оптимальный диапазон — от 30 до 80 фраз на статью объемом 5 000-10 000 знаков. Меньше 30 — семантическое облако слабое, выше 100 — нейросеть начинает механически вставлять слова без смыслового контекста. Список нужно ранжировать по частоте встречаемости у конкурентов: топ-20 фраз — обязательные, остальные — желательные. Такой приоритет помогает модели распределить внимание корректно.
Почему ии написать текст для поста в соцсетях — это другая задача, чем SEO-статья?
Пост для соцсетей оптимизируется под вовлеченность: короткие предложения, эмоциональные крючки, призыв к действию в первых строках. SEO-статья — под семантическое соответствие запросу и поведенческие факторы: время на странице, глубина скролла, возврат в выдачу. Промпт для поста и для статьи строятся по-разному. Смешивать логику не стоит — результат получится ни туда ни сюда.
Как часто нужно обновлять LSI-семантику для существующих статей?
Выдача меняется. Конкуренты обновляют контент, Яндекс переранжирует страницы, в нише появляются новые термины. Рекомендуемая частота пересбора семантики для активно ранжируемых страниц — раз в 3-4 месяца. Если позиция начала падать без изменений на сайте — это первый сигнал, что конкурент обновил семантику, а ваша страница отстала.
Нейросеть написать текст сгенерировать — это одно и то же, что рерайт конкурентов?
Нет, принципиально другое. Рерайт берет чужой текст и перефразирует его — это риск для уникальности и риск воспроизвести ошибки конкурента. Правильная генерация с парсингом SERP извлекает только структуру и семантику — слова и темы, которые конкуренты используют — и строит оригинальный текст с нуля. Содержание новое, семантическое поле — совпадающее с топом. Именно это и нужно Яндексу.
Как ТекстЗавод обеспечивает адаптацию под Яндекс, а не только под Google?
Платформа парсит выдачу именно Яндекса, а не Google. Это важно: алгоритмы разные, выдача по одному запросу может отличаться на 30-40% состава страниц. Дополнительно — интеграция с Яндекс Wordstat для сбора частотности и учет региональных факторов ранжирования, которые актуальны для Рунета. Западные сервисы такой адаптации не дают — они ориентированы на Google, и их данные по Яндексу либо неточные, либо отсутствуют.
Итог — что реально работает в 2026 году
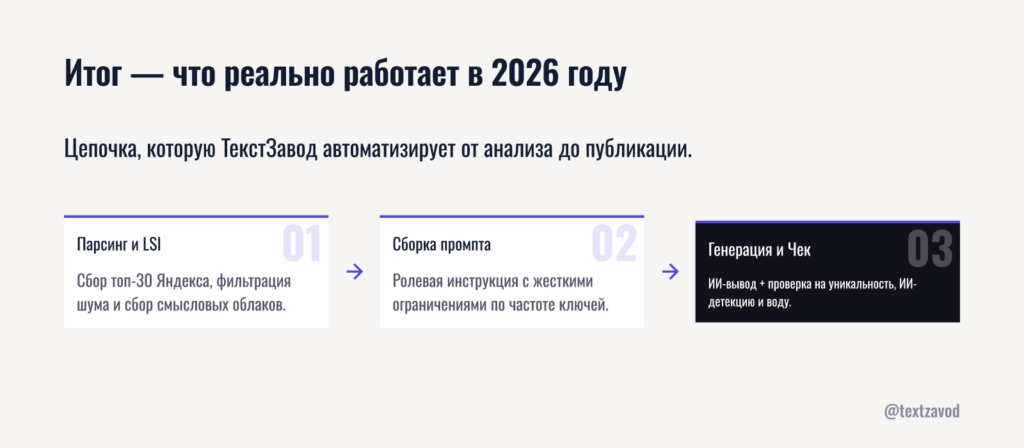
Никакой магии. Только алгоритмы. Яндекс оценивает страницы по семантической близости к запросу — и выигрывают те, кто собрал это семантическое облако у конкурентов, а не придумал его из головы.
Цепочка простая: парсинг топ-30 → фильтрация шума → список LSI-фраз → ролевой промпт с ограничениями → генерация через Gemini или Claude → тройная проверка метрик. Каждый шаг автоматизируется. Ручной труд остается только там, где нужна экспертная правка фактуры.
ТекстЗавод закрывает эту цепочку полностью: от SERP-анализа до публикации в CMS — WordPress, Modx или Bitrix. 25 статей за 15 минут — это не рекламный слоган, это результат автоматизации каждого этапа без потери контроля над качеством.
Зарегистрируйтесь на textzavod.ru и введите промокод «Завод03» — получите три статьи бесплатно. Проверьте на своей нише, как работает SERP-анализ в связке с ИИ-генерацией.