Разбираем механику обхода AI-детекторов через SERP-анализ и LSI-фразы: как делать контент, который залетает в топ-10 без ручной правки каждого абзаца
Написать текст нейросетью онлайн и сразу получить позиции — так не работает уже с 2024 года. Яндекс научился распознавать машинные паттерны в структуре и лексике, и голый GPT-вывод без фактуры и семантики летит на 20+ позиций. Путь к топу короче, чем кажется: SERP-анализ перед генерацией, правильная плотность ключей и трехэтапный контроль качества перед публикацией.
В этой статье разберем четыре блока: почему стандартный AI-текст не ранжируется, как парсинг выдачи меняет качество генерации, как вписать ключевые запросы без риска фильтра «Баден-Баден» и что проверять перед тем, как нажать «Опубликовать».
Почему стандартный GPT-текст больше не ранжируется

Ситуация стандартная. Специалист берет ключ, отправляет его в ChatGPT или любой другой ИИ чат, получает текст на 5 000 знаков и публикует. Через месяц — позиции 30-50, трафик нулевой.
Проблема не в самом факте использования нейросети. Проблема в том, что модель пишет по своим внутренним паттернам, а не по структуре реальной выдачи. Яндекс в 2025-2026 году помечает такие материалы как «малополезные» — это прямая цитата из документации о принципах ранжирования.
Три механизма, по которым Яндекс вычисляет AI-текст
Первый — нейроштампы в лексике. Модели склонны использовать одни и те же конструкции: «в современном мире», «следует отметить», «данная статья рассмотрит». По данным тестов text.ru Neurotools в 2025 году, алгоритм определяет машинное происхождение в 85% случаев именно через повторяющиеся синтаксические конструкции.
Второй — отсутствие LSI-фраз из реальной выдачи. Среднестатистический AI-текст содержит на 30% меньше уникальных слов по сравнению с материалами авторов из топ-10. Модель оперирует общеизвестными понятиями, но не знает, какие именно подзаголовки и формулировки уже приносят трафик лидерам ниши. Это легко проверить: возьмите любую статью из топ-5 Яндекса по конкурентному запросу и сравните словарный запас с чистым GPT-выводом. Разница очевидна.
Третий — нулевая добавочная ценность. Поисковик смотрит не только на структуру, но и на содержание. Если статья дублирует то, что уже написано в топ-10, без новых цифр, конкретных примеров или экспертной позиции — она не выйдет выше 20-й позиции. Это подтверждается тем, как работает E-E-A-T: Google и Яндекс оба требуют демонстрации реального опыта.
Что именно проверяет алгоритм
Яндекс анализирует поведенческие факторы: если пользователь уходит со страницы через 15 секунд, сигнал однозначный. AI-текст без структуры, без конкретики и с шаблонными фразами дает именно такое поведение.
Кроме того, алгоритм смотрит на распределение семантики внутри текста. Равномерный ритм предложений — один из маркеров машинного письма. Живой автор чередует длинные и короткие конструкции, вставляет ремарки, меняет темп. Модели этого не делают по умолчанию.
Вывод прямой: написать текст через ИИ можно и нужно, но без предварительного SERP-анализа результат предсказуем — позиции за пределами топ-30.
Парсинг SERP как фундамент для генерации
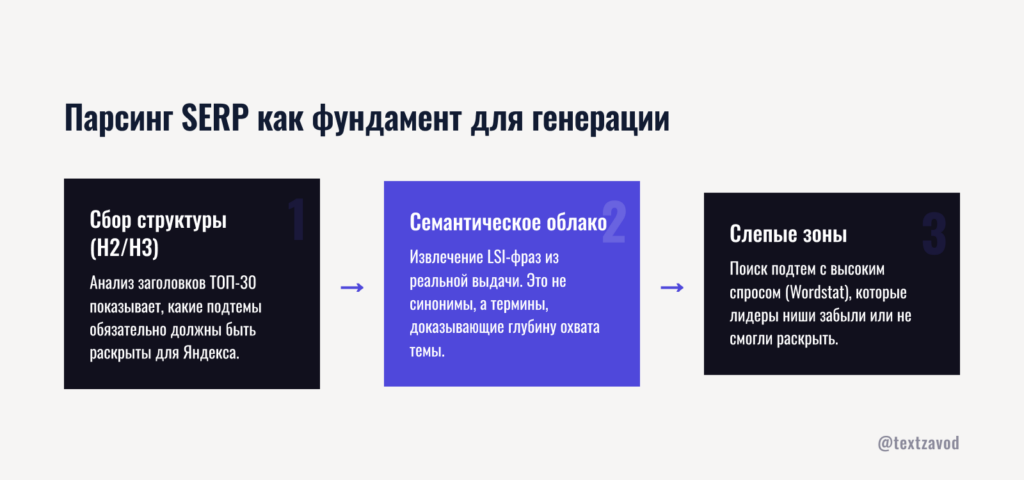
Прежде чем попросить нейросеть написать текст, нужно дать ей правильное задание. Без данных о выдаче — это работа вслепую.
Парсинг топ-30 по целевому запросу решает три задачи: показывает, какие подзаголовки уже работают у конкурентов, вытаскивает скрытые LSI-фразы, которые поисковик считает релевантными, и выявляет «слепые зоны» — темы, которые лидеры ниши не раскрыли. Именно в этих зонах живет возможность обойти конкурентов без борьбы за их позиции.
Как работает сбор семантического облака
Стандартный процесс выглядит так. Берем основной ключ, прогоняем его через Яндекс Wordstat и получаем список связанных запросов. Но этого недостаточно: Wordstat показывает частотность, а не релевантность к конкретной странице.
Следующий шаг — анализ самой выдачи. Из топ-30 извлекаем заголовки H2 и H3, мета-описания и первые абзацы. На выходе получаем семантическое облако: набор слов и фраз, которые Яндекс считает тематически связанными с запросом. Это не синонимы ключа — это сопутствующие понятия, которые сигнализируют поисковику о полноте раскрытия темы.
Пример: по запросу «написать текст нейросеть онлайн» в семантическое облако попадут фразы вроде «промпт для генерации», «уникальность статьи», «фильтр Яндекса», «плотность ключей», «SEO-оптимизация контента». Ни одна из них не является прямым ключом, но их присутствие в тексте влияет на ранжирование.
Поиск слепых зон конкурентов
Мы в ТекстЗаводе используем связку Gemini и Claude для этой задачи. Gemini анализирует структуру статей из топ-30 и составляет матрицу покрытия тем: что раскрыто у каждого конкурента, что — нет. Claude сопоставляет эту матрицу с частотными данными из Wordstat и выдает список подтем с высоким спросом, но слабым покрытием в текущей выдаче.
На практике это выглядит иначе, чем кажется. Не «напиши статью про X», а «вот структура топ-30, вот семантическое облако, вот три подтемы, которые конкуренты не раскрыли — сделай статью, закрывающую все это». Разница в качестве результата — принципиальная.
Структура правильного промпта для генерации
Качество вывода нейросети прямо зависит от детальности задания. Это подтверждается во всех обзорах инструментов для AI-копирайтинга 2025-2026 годов. Слабый промпт дает слабый текст — независимо от того, используете ли вы ChatGPT, YandexGPT, Gemini или Claude.
Рабочий промпт для SEO-статьи включает:
- Целевой запрос и намерение пользователя — информационный, транзакционный или навигационный интент. Это фундамент: смешение интентов в одной статье снижает релевантность.
- Список LSI-фраз из SERP-анализа — не менее 15-20 фраз, распределенных по тексту. Нейросеть должна получить их явно, иначе будет генерировать из своей базы знаний, а не из реальной выдачи.
- Структуру конкурентов с пометками — какие разделы взять за основу, какие расширить, какие не трогать. Без этого модель изобретает колесо.
- Требования к объему и плотности ключей — конкретные цифры: 8 000-10 000 знаков, основной ключ 1,5%, дополнительные ключи по одному разу.
- Формат подачи — абзацы по 3-5 предложений, списки с пояснениями, таблица для сравнений.
| Элемент промпта | Влияние на качество | Частая ошибка |
|---|---|---|
| Целевой запрос + интент | Высокое | Смешение информационного и коммерческого интента |
| LSI-фразы из SERP | Критическое | Не указывать или указывать менее 10 фраз |
| Структура конкурентов | Высокое | Давать только тему без примеров H2/H3 |
| Требования к объему | Среднее | Не указывать — модель пишет сколько хочет |
| Параметры форматирования | Среднее | Получать один сплошной текст без структуры |

Почему автоматизация этого процесса экономит часы
Ручной SERP-анализ по одному запросу занимает 1,5-2 часа. На 15 статей в месяц — это 22-30 часов только на подготовку. Автоматизация через платформы, которые парсят выдачу и строят семантическое облако за минуты, меняет экономику производства контента.
ТекстЗавод делает именно это: парсит топ-30 по запросу, собирает данные из Wordstat, строит структуру статьи на основе реальной выдачи — и только потом запускает генерацию через Gemini или Claude. Попробуйте этот подход сами: первые три статьи бесплатно по промокоду Завод03.
Как вписать ключи без переспама

Плотность ключевых слов выше 2,5% в 2026 году — прямой путь к фильтру «Баден-Баден». Это не предположение: Яндекс в своей официальной документации прямо указывает на риски переоптимизации, и санкции применяются автоматически.
Но проблема не только в переспаме. Обратная ошибка — слишком низкая плотность — тоже снижает позиции. Алгоритм должен понять, о чем страница. Рабочий диапазон для основного ключа: 1,0-2,0% по Advego. Для дополнительных запросов — по одному вхождению на 500-800 знаков.
Разделение интентов — критически важный шаг
Частая ошибка при использовании ИИ для написания текста для поста или информационной статьи — вставка транзакционных запросов туда, где они не нужны. Фраза «купить», «заказать», «цена» в информационной статье смешивает интенты и снижает релевантность страницы по обоим типам запросов.
Модели делают это часто, потому что в их обучающих данных много коммерческих текстов. Если вы используете ИИ чат для написания текста на информационный запрос — явно указывайте в промпте: «только информационный контент, без коммерческих призывов к действию внутри основного текста».
Как LSI-фразы заменяют повторы ключа
LSI-фразы для SEO работают как семантические сигналы: они показывают поисковику, что страница полно раскрывает тему, не повторяя один и тот же ключ десятки раз.
Механика простая. Основной ключ «написать текст нейросетью онлайн» входит в текст 2-3 раза. Вместо четвертого повтора — LSI-фраза: «сгенерировать статью через ИИ», «автоматическая генерация контента», «работа с языковой моделью». Поисковик понимает контекст, пользователь читает живой текст, а не набор одинаковых фраз.
Для нейросети это тоже задача промпта. Явно укажите список LSI-фраз и инструкцию: «используй каждую фразу один раз, равномерно по тексту, не ставь два LSI-выражения в один абзац». Без этой инструкции модель будет кластеризовать похожие фразы рядом — и создавать локальный переспам.
Интент пользователя как фильтр для ключей
Намерение пользователя определяет, какие ключи допустимы в конкретном тексте. Разберем на примере:
- Информационный запрос «как написать текст с помощью GPT» — пользователь хочет инструкцию. Нужны: пошаговые объяснения, примеры промптов, сравнение инструментов. Не нужны: цены, призывы купить подписку внутри основного текста.
- Транзакционный запрос «написать текст через ИИ заказать» — пользователь готов платить. Нужны: условия, цены, примеры работ, гарантии.
- Навигационный запрос «ИИ чат написать текст бесплатно» — пользователь ищет конкретный инструмент. Нужен: прямой ответ с ссылкой.
Смешивать эти форматы в одной статье — значит терять позиции по всем трем типам запросов одновременно. Модели делают это по умолчанию. Контролируйте через промпт.
Равномерное распределение — не магия, а математика
Практическое правило: один уникальный ключ или LSI-фраза на каждые 500 знаков текста. При объеме 8 000 знаков это 16 семантических единиц. Из них 2-3 — основной ключ, остальные — дополнительные запросы и LSI.
Нейросеть без явного задания часто концентрирует ключи в первом и последнем абзацах. Это создает неравномерное распределение, которое алгоритм Яндекса считывает как сигнал манипуляции. Решение: в промпте указывать конкретные разделы, в которые должны попасть конкретные фразы.
Тройная проверка качества перед публикацией

Генерация — это половина работы. Вторая половина — контроль качества перед тем, как страница попадет в индекс. Пропустить этот этап значит потратить ресурсы впустую: статья выйдет, но не будет ранжироваться.
Три обязательных проверки: уникальность, AI-детекция и технический SEO-аудит страницы.
Уникальность через text.ru — норма и методология
Стандарт для SEO-статьи в 2025-2026 году: не менее 90% по глубокой проверке на text.ru. Поверхностная проверка дает ложные цифры — она не ловит перефразированные фрагменты и синтаксические копии. Только глубокая.
Откуда берется низкая уникальность в AI-тексте? Модели обучены на огромных корпусах текстов, и при генерации воспроизводят типичные конструкции из обучающей выборки. Особенно это заметно в описаниях процессов («сначала нужно», «следующий шаг»), определениях терминов и вводных абзацах.
Если уникальность ниже 90% — не переписывайте вручную весь текст. Определите конкретные блоки с низкими показателями и перегенерируйте их через другую модель. Например, если основной текст написан через Gemini, проблемные участки прогоните через Claude 3.5 Sonnet — у него другие паттерны генерации, и пересечений с популярными источниками меньше.
AI-детекция — зачем она нужна в 2026 году
Инструменты вроде GigaCheck и Neurotools от text.ru анализируют статистические характеристики текста: распределение длины предложений, частотность слов, энтропию лексики. Если все предложения примерно одной длины и лексика равномерно «причесана» — это маркер машинного письма.
Фильтры Яндекса 2026 года учитывают эти сигналы. Прямого подтверждения автоматического пессимизирования за AI-детекцию нет, но корреляция между высоким AI-score и низкими позициями прослеживается на практике у многих специалистов.
Что снижает AI-score:
- Burstiness — намеренное чередование длины предложений. Три коротких, одно длинное с придаточным, снова короткое. Живой автор пишет именно так.
- Конкретные факты и цифры — модели избегают конкретики без явного указания в промпте. Добавьте в промпт требование: «включи конкретные цифры, даты, названия инструментов в каждом разделе».
- Разговорные ремарки — «на практике это работает иначе», «проверили — работает», «по факту». Модели их не генерируют без прямого указания.

Технический SEO-аудит после генерации
Даже идеально написанная статья не будет ранжироваться, если технические параметры страницы не соответствуют требованиям. Проверочный список минимальный:
- Title — основной ключ в первых 55-65 символах, без дублирования H1.
- H1 — один на страницу, содержит основной ключ, 50-70 символов.
- Alt-теги изображений — содержат ключи или LSI-фразы, не дублируют друг друга.
- Мета-описание — 140-155 символов, основной ключ в первой половине, есть призыв к действию.
- Внутренние ссылки — минимум 2-3 на связанные страницы сайта.
- Скорость загрузки — изображения сжаты, лишние скрипты убраны.
Технический аудит удобно автоматизировать. ТекстЗавод проверяет вхождение ключей в Title, H1 и alt-теги автоматически после генерации — это часть встроенного SEO-аудита платформы. Результат виден до публикации, а не после индексации.
Контроль качества как система, а не разовое действие
Сухой остаток: разовая проверка перед публикацией — это минимум. Для сайтов с 15+ статьями в месяц нужна система: стандарт качества на входе (требования к промпту), автоматические проверки на выходе (уникальность, AI-детекция, технический аудит) и мониторинг позиций через 4-6 недель после публикации.
Без мониторинга невозможно понять, что именно влияет на результат. Отслеживайте позиции по целевым запросам и поведенческие метрики: время на странице, процент отказов, глубину скролла. Это дает базу доказательств для оптимизации следующего цикла генерации.
Попробовать полный цикл — от анализа выдачи до публикации — можно на textzavod.ru. Промокод Завод03 дает доступ к трем статьям без оплаты.
SEO-продвижение через контент и GEO-оптимизация

Прежде чем перейти к вопросам, стоит сказать о контексте: зачем вообще вкладываться в качественный AI-контент, если можно просто запустить рекламу в Яндекс.Директе.
Разница фундаментальная. Трафик из Директа существует, пока существует бюджет. Статья в топ-10 работает месяцами — и каждый месяц приводит читателей без дополнительных затрат. При этом человек, который нашел материал через поиск, прочитал его и убедился в экспертизе, приходит к покупке уже подготовленным. Это принципиально другая конверсия по сравнению с прерванным баннером.
Отдельная история — GEO-оптимизация. Это продвижение в нейровыдаче: Яндекс Нейро, Google AI Overview, ответы ChatGPT на информационные запросы. Ниша пока почти без конкурентов — большинство сайтов оптимизируют контент под классический поиск и не думают о том, как их цитируют языковые модели. Войти в этот канал сейчас значит занять позицию до того, как туда придет конкуренция.
ТекстЗавод генерирует статьи с учетом требований и классического поиска, и нейровыдачи: chunk-структура для цитирования, прямые ответы после каждого H2, FAQ-блоки с разговорными вопросами. Это не два разных процесса — это один правильно настроенный промпт.
Часто задаваемые вопросы

Можно ли написать текст нейросетью онлайн бесплатно и получить SEO-результат?
Да, но с оговорками. Бесплатные инструменты дают текст без SERP-анализа и без контроля плотности ключей. Для единичных статей это приемлемо при условии ручной доработки. Для масштабного производства — нет: без автоматизации анализа выдачи каждая статья требует 1,5-2 часа подготовки вручную, что съедает всю экономию от генерации.
Какую нейросеть лучше использовать для SEO-текстов на русском языке?
В 2026 году для русскоязычного контента хорошо работают Claude 3.5 Sonnet и Gemini 1.5 Pro. YandexGPT через Яндекс Нейро понимает русскоязычный контекст и особенности Рунета, но генерирует более короткие тексты. ChatGPT сильнее в английском, но при детальном промпте дает приемлемое качество и на русском. Оптимально — комбинировать: основной текст через Claude или Gemini, проблемные блоки перегенерировать через другую модель.
Как проверить, что текст не попадет под фильтр «Баден-Баден»?
Проверяйте плотность ключей через Advego: основной запрос должен занимать 1,0-2,0% от общего объема, все ключи вместе — не более 3-4%. Дополнительно смотрите на академическую тошноту по Advego: норма до 9%. Если оба показателя в норме и текст прошел проверку уникальности на 90%+ — риск фильтра минимален.
Что такое LSI-фразы для SEO и откуда их брать?
LSI-фразы — это слова и выражения, тематически связанные с основным запросом. Поисковик использует их как сигнал полноты раскрытия темы. Брать их нужно из реальной выдачи: смотрите на H2 и H3 в статьях топ-10, используйте блок «Люди также ищут» в Яндексе и Google, анализируйте мета-описания конкурентов. Инструменты вроде Wordstat показывают связанные запросы, но SERP-анализ дает более точную картину.
Нужно ли редактировать AI-текст вручную перед публикацией?
Зависит от цели. Для высококонкурентных запросов — редактура нужна: добавьте экспертную позицию, конкретные кейсы из практики, актуальные данные. Для информационных запросов с низкой конкуренцией достаточно автоматических проверок и технического аудита. Ключевой принцип: если статья не добавляет ничего нового по сравнению с топ-10 — редактура не спасет.
Как долго статья, написанная нейросетью, держится в топе?
При правильной подготовке — от 6 месяцев до нескольких лет. Срок зависит от конкурентности ниши и частоты обновления информации в теме. Статьи по «вечнозеленым» информационным запросам держат позиции дольше всего. Для новостных и быстро меняющихся тем нужно обновлять контент каждые 6-12 месяцев. Это одна из причин, почему автоматизация производства контента окупается: обновить и перегенерировать статью быстрее, чем писать новую.
Сколько статей в месяц реально производить с автоматизацией?
Без автоматизации один специалист закрывает 8-12 статей в месяц с учетом SERP-анализа и редактуры. С платформой вроде ТекстЗавода — до 25 статей за 15 минут генерации плюс время на финальный контроль. Реальная производительность при работе с 15+ сайтами: 100+ материалов в месяц при команде из 2-3 человек.