Технология массового создания уникального контента для гео-зависимых запросов — масштабируем бизнес без раздувания штата редакторов
Яндекс склеивает страницы, где разница только в названии города. Чтобы этого не происходило, каждая региональная страница должна отличаться от соседней минимум на 70% по тексту — иначе поисковик выберет одну «каноническую» и скроет остальные из выдачи. Массовая джипити генерация текста решает эту задачу без найма дополнительных копирайтеров: при правильной архитектуре шаблонов 100 страниц выходят уникальными, оптимизированными и готовыми к публикации.
В этой статье разберём три уровня проблемы: почему дубли убивают региональное продвижение, как выстроить алгоритм массовой генерации без потери уникальности и как автоматизировать публикацию, не теряя контроль над качеством.
Ловушка одинаковых страниц услуг и почему она дорого обходится

Ситуация типичная. Сеть из 20 филиалов — и для каждого нужна своя страница «Ремонт холодильников в [Город]». Маркетолог копирует один текст, меняет топоним в заголовке и мета-тегах. Кажется, что задача закрыта. На самом деле — только что создано 20 дублей.
Яндекс обрабатывает такие страницы через механизм группировки похожих документов. Алгоритм сравнивает контент не по заголовку, а по всему текстовому телу страницы. Если совпадение превышает 30-40%, система выбирает одну страницу как «основную» и убирает остальные из основной выдачи. Региональные пользователи просто не видят ваш сайт.
Уникализация на 70% и выше — не произвольная цифра. Это порог, при котором Яндекс воспринимает страницы как самостоятельные документы с разным намерением пользователя. Речь не о замене двух-трёх слов: нужно переписывать вводные абзацы, блоки с преимуществами, примеры работ, FAQ и описание процесса.
Во сколько обходится ручной путь
Фрилансер-копирайтер берёт за SEO-текст объёмом 3-5 тысяч знаков от 500 до 1 500 рублей — в зависимости от тематики и опыта. Для 100 региональных страниц это 50 000–150 000 рублей только за написание. Плюс техническое задание, правки, проверка на антиплагиат и загрузка в CMS — ещё 2-4 недели работы контент-менеджера.
Итог: два месяца и бюджет от 150 000 рублей на старт регионального продвижения. При этом тексты всё равно получаются структурно похожими, потому что разные авторы используют одинаковые шаблоны рассуждений.
Что Яндекс считает «тонким» контентом
Проблема не только в дублях. Есть второй риск — пессимизация за низкокачественные страницы. Яндекс с 2024 года активнее применяет фильтры к страницам, которые:
- содержат менее 500-700 слов при высокой конкуренции в нише;
- не отвечают на конкретный локальный запрос (цена, срок, адрес, контакты);
- генерируются шаблонно без учёта специфики региона.
Гео-зависимые запросы — отдельная история. Пользователь в Екатеринбурге пишет «ремонт кофемашин цена» и ожидает увидеть местные компании с реальными расценками. Страница без упоминания города, без конкретных цифр и без локальных сигналов проигрывает даже слабым конкурентам, у которых эти элементы есть.
Три канала привлечения клиентов для регионального бизнеса
Прежде чем говорить о масштабировании контента, зафиксируем контекст: зачем вообще нужны сотни страниц услуг.
Первый канал — контекстная реклама в Яндекс.Директе. Быстрый старт, но трафик существует ровно столько, сколько пополняется бюджет. Стоп кампании — стоп клиентов. Для 50 регионов это 50 отдельных рекламных кампаний с постоянными затратами.
Второй канал — SEO-продвижение через контент. Страница, которая попала в топ-3 выдачи, работает месяцами без дополнительных вложений. Написали один раз — получаете трафик год. Это принципиально другая экономика по сравнению с рекламой: инвестиция амортизируется, а не сгорает.
Отдельного внимания заслуживает GEO-оптимизация — попадание в нейровыдачу Яндекс Алисы, Google AI Overview и ChatGPT. Когда пользователь задаёт вопрос голосовому ассистенту или нейросети, та цитирует конкретные источники. Эта ниша пока почти пустая: большинство сайтов ещё не адаптировали структуру под нейроблоки. Зайти сейчас — значит занять позицию до того, как конкуренты осознают ценность этого канала.
Ещё один аргумент в пользу SEO: человек, нашедший статью через поиск, уже прошёл половину пути к покупке самостоятельно. Он сам ввёл запрос, сам выбрал ссылку, сам изучил материал. К моменту обращения он прогрет и готов к разговору — в отличие от пользователя, которого прервал рекламный баннер.
Для создания таких статей удобно использовать ТекстЗавод: платформа анализирует топ выдачи по каждому запросу, строит контент-план и генерирует SEO- и GEO-оптимизированные тексты. Те самые, которые будут планомерно приводить прогретых читателей.
Третий канал — агрегаторы и маркетплейсы (Авито, Яндекс.Услуги, 2ГИС). Хорошее дополнение, но высокая конкуренция по цене и зависимость от алгоритмов площадки.
Масштабирование контента напрямую усиливает второй канал. Чем больше релевантных региональных страниц — тем шире семантическое облако сайта и тем больше точек входа для потенциальных клиентов.
Алгоритм массовой генерации в ТекстЗаводе
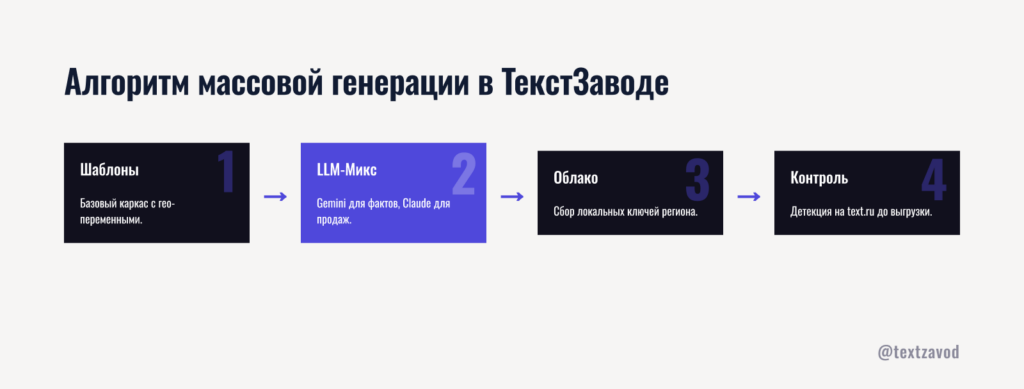
Массовая генерация текстов chat gpt без архитектуры — это быстрый способ получить 100 одинаковых страниц с разными городами. Нужен системный подход: шаблон с переменными, несколько LLM-моделей для вариативности и контроль уникальности перед выгрузкой.
Шаг 1. Шаблон с переменными как основа масштабирования
Базовый шаблон — не просто текст с плейсхолдерами вида «{город}». Это структурная схема страницы, где каждый блок может варьироваться независимо.
Переменные делятся на два типа. Первый — фактические данные, которые вы вносите вручную или загружаете из таблицы:
- название города и региона в нужном падеже;
- цена услуги (может различаться по регионам на 15-40%);
- срок выполнения работ (зависит от логистики);
- адрес ближайшего офиса или сервисного центра;
- имя регионального менеджера для контактного блока.
Второй тип — семантические переменные, которые задают «угол» текста. Для одного города акцент делается на скорости, для другого — на гарантии, для третьего — на стоимости. Это и обеспечивает структурное различие страниц, а не только лексическое.
На примере наших проектов: шаблон с 8-10 переменными даёт уникальность 75-85% между страницами при прогоне через антиплагиат. Это выше порога, который Яндекс считает достаточным для самостоятельных документов.
Шаг 2. Разные LLM-модели для вариативных блоков
Здесь начинается настоящая работа с автоматизацией публикаций. ТекстЗавод работает на двух моделях — Google Gemini и Anthropic Claude. Это не дублирование, а целенаправленное использование разных стилистических паттернов.
Gemini лучше справляется с информационными блоками: техническими описаниями, перечнями характеристик, структурированными FAQ. Claude сильнее в убеждающих и продающих фрагментах: вводных абзацах, блоках с преимуществами, призывах к действию.
Практическая схема для 100 страниц:
| Блок страницы | Модель | Назначение |
|---|---|---|
| Заголовок H1 и мета-тег Title | Claude | Убедительность, точность ключа |
| Вводный абзац (лид) | Claude | Захват внимания, локальный контекст |
| Описание услуги (3-5 абзацев) | Gemini | Информационная плотность |
| Блок преимуществ | Claude | Продающий тон |
| Процесс работы (шаги) | Gemini | Чёткая структура |
| FAQ (5-7 вопросов) | Gemini | Охват длинного хвоста запросов |
| Призыв к действию | Claude | Конверсионный текст |
| Meta Description | Claude | CTR в выдаче |

Чередование моделей по блокам само по себе повышает вариативность финального текста. Gemini и Claude строят предложения по-разному — разный порядок слов, разные синтаксические конструкции. Это снижает вероятность того, что две страницы окажутся структурно идентичными даже при одинаковом шаблоне.
Шаг 3. Семантическое облако для каждого региона
Перед генерацией каждой страницы ТекстЗавод парсит топ-30 Яндекса по целевому запросу в конкретном регионе. Это критически важно: выдача по запросу «ремонт холодильников Краснодар» и «ремонт холодильников Новосибирск» может различаться существенно — разные конкуренты, разные форматы страниц-победителей, разные ожидания пользователей.
На основе анализа строится региональное семантическое облако: ключи, LSI-фразы, вопросы из раздела «Люди также спрашивают», характерные для данного рынка. Эти данные становятся частью промпта для генерации — и страница получается оптимизированной под конкретный региональный запрос, а не под усреднённый федеральный.
Шаг 4. Контроль уникальности до выгрузки
Каждый сгенерированный текст проходит проверку через text.ru перед тем, как попасть в очередь на публикацию. Это не опциональный шаг — это фильтр, без которого масштабирование теряет смысл.
Важный нюанс: исследователи из ИТМО разработали алгоритм, который определяет авторство текста с точностью 94% — и это на русскоязычных материалах. Система «Антиплагиат» уже маркирует тексты, сгенерированные начиная с GPT-2. Страницы, написанные однотипно через chat gpt нейросеть, детектируются и могут получить пессимизацию — даже если формально уникальны по шинглам.
Поэтому в ТекстЗаводе двойной фильтр: антиплагиат проверяет текстовые совпадения, AI-детекция через text.ru оценивает вероятность машинного происхождения. Страницы, не прошедшие порог — возвращаются на повторную генерацию с изменёнными параметрами промпта.
Реальные цифры по скорости
Ручной путь для 100 страниц: 60-80 рабочих часов копирайтеров плюс 20-30 часов редактуры и загрузки. Итого — 2-3 недели при команде из 3-4 человек.
В ТекстЗаводе 25 страниц генерируются за 15 минут. Сотня — за час с небольшим, с учётом очереди на проверку. Контент-менеджер при этом занимается только финальной верификацией фактических данных: цен, адресов, контактов.
Попробуйте сами — запустите первые 25 страниц за 15 минут в ТекстЗаводе. Промокод Завод03 активирует три статьи бесплатно для теста на реальном проекте.
Типичные ошибки при массовой генерации
Разберём, что чаще всего идёт не так:
Один промпт для всех регионов. Без региональной адаптации семантики страницы получаются формально уникальными, но нерелевантными локальным запросам. Яндекс это видит по поведенческим факторам: пользователь открывает страницу и уходит, не найдя нужных данных.
Переменные только в заголовках. Если тело страницы идентично, а город упоминается только в H1 и первом абзаце — это дубль. Алгоритм Яндекса анализирует весь документ, а не только теги.
Игнорирование фактических данных. Генерация текста без реальных цен и сроков создаёт страницы-«пустышки». GPT-5, по данным OpenAI, галлюцинирует на 45% реже, чем GPT-4o при включённом веб-поиске — но это не означает нулевой риск. Цены и адреса всегда вносятся вручную из актуальной базы данных.
Отсутствие локальных сигналов. Упоминание районов города, местных ориентиров, региональных особенностей — это то, что отличает страницу для живого пользователя от технически оптимизированного, но безликого текста.
Массовая публикация без паузы. Загрузка 100 новых страниц за один день может быть воспринята как искусственное наращивание контента. Оптимальный темп — 10-20 страниц в день с постепенным наращиванием.
Прямая публикация в CMS и контроль качества финального результата

Сгенерированный текст — это ещё не опубликованная страница. Между генерацией и индексацией есть несколько шагов, каждый из которых можно автоматизировать или потерять на нём несколько часов.
Экспорт в CMS без ручной загрузки
ТекстЗавод интегрируется напрямую с WordPress, Bitrix и ModX через API. Это убирает самый трудоёмкий этап работы контент-менеджера — ручную загрузку каждой статьи.
Что происходит при экспорте:
- текст передаётся в нужный раздел сайта с правильной категорией и тегами;
- Title и Description заполняются автоматически на основе данных, сгенерированных при создании текста;
- атрибуты Alt для изображений прописываются с учётом ключевых фраз страницы;
- URL-slug формируется из основного ключа с транслитерацией.
Для Bitrix и ModX это особенно ценно: ручная загрузка 100 страниц через интерфейс этих CMS занимает 6-8 часов у опытного контент-менеджера. При автоматическом экспорте — 20-30 минут на настройку и запуск задачи.

Автоматическое заполнение мета-тегов
Мета-теги — больная точка при массовом контенте. Стандартная ситуация: тексты написаны, но Description у 80 страниц из 100 либо пустой, либо скопирован с главной. Поисковик формирует сниппет самостоятельно — и не всегда удачно.
В ТекстЗаводе мета-теги генерируются как отдельный элемент для каждой страницы. Title строится по формуле: основной ключ + локальный уточнитель + триггер (цена, срок, гарантия). Description — 140-155 символов с ключом в первой половине и конкретным УТП.
Пример для страницы «Ремонт холодильников Самара»:
- Title: Ремонт холодильников в Самаре — цены от 990 руб., выезд за 2 часа
- Description: Починим холодильник любой марки в Самаре. Диагностика бесплатно, гарантия 12 месяцев. Вызов мастера за 2 часа — звоните прямо сейчас.
Такой сниппет даёт конкретику, которую пользователь видит ещё в выдаче, — и кликает охотнее.
Двойная верификация: AI-детекция плюс человек
Автоматизация публикаций не отменяет финальный контроль. Схема работает в два этапа.
Первый этап — машинная верификация. Каждая страница перед публикацией проходит через встроенный модуль проверки: антиплагиат фиксирует процент совпадений с уже проиндексированными документами, AI-детекция оценивает «машинность» текста по метрикам text.ru. Страницы с показателями ниже порога автоматически уходят на регенерацию.
Второй этап — человеческая проверка фактов. Это единственное, что нельзя делегировать алгоритму полностью. Контент-менеджер просматривает выборку из 10-15% страниц и проверяет:
- соответствие цен актуальному прайсу;
- правильность адресов и контактных данных;
- отсутствие «галлюцинаций» — выдуманных характеристик услуги или несуществующих акций.
GPT-5 действительно галлюцинирует реже предыдущих версий, но риск не нулевой. Факты о конкретном бизнесе — цены, сроки, гарантии — модель не знает по умолчанию. Они должны поступать из структурированного исходного материала, который вы передаёте в промпт.
Экономия на операционных расходах
Посчитаем конкретно. Контент-менеджер с зарплатой 60 000 рублей тратит на ручную загрузку 100 страниц (с мета-тегами, изображениями и проверкой) около 40 рабочих часов. Это примерно треть месячного рабочего времени — 20 000 рублей фактических трудозатрат только на публикацию, без учёта написания.
При автоматическом экспорте через API те же 100 страниц загружаются за 2-3 часа. Разница — 37-38 часов, которые специалист тратит на задачи с более высокой отдачей: анализ позиций, работу с поведенческими факторами, настройку внутренней перелинковки.
Забудьте о рутинной загрузке — попробуйте автоматическую публикацию на сайт с промокодом Завод03 и оцените разницу на первом же проекте.
Структура рабочего процесса в цифрах
| Этап | Ручной режим | С ТекстЗаводом |
|---|---|---|
| Сбор семантики для 100 регионов | 16-20 ч | 1-2 ч (парсинг Wordstat) |
| Написание текстов | 60-80 ч | 1-2 ч (генерация) |
| Проверка уникальности | 10-15 ч | Автоматически |
| Загрузка в CMS | 30-40 ч | 2-3 ч (API) |
| Заполнение мета-тегов | 8-10 ч | Автоматически |
| Проверка фактов | 5-8 ч | 5-8 ч (без изменений) |
| Итого | 129-173 ч | 9-13 ч |
Сокращение трудозатрат в 10-15 раз — это не маркетинговая цифра. Это результат делегирования алгоритмам тех операций, где скорость и воспроизводимость важнее творчества.
Частые вопросы о массовой генерации страниц услуг

Яндекс вообще нормально относится к AI-контенту?
Яндекс оценивает качество контента, а не его происхождение. Если страница отвечает на запрос пользователя, содержит актуальные факты и хорошо читается — она будет ранжироваться. Проблема возникает, когда AI-контент шаблонный, без локальной специфики и с признаками массовой генерации без редакторской обработки. Правильно выстроенный процесс с двойной проверкой и фактическими данными из реального бизнеса эту проблему снимает.
Какой минимальный объём текста нужен для региональной страницы услуги?
Для конкурентных ниш — от 2 500 до 4 000 слов с учётом FAQ, блока преимуществ и описания процесса. В низкоконкурентных регионах иногда достаточно 1 500-2 000 слов. Но ориентироваться нужно не на объём, а на полноту ответа: страница должна закрывать все вопросы пользователя, которые видны в топ-10 выдачи по данному запросу.
Как избежать того, чтобы страницы конкурировали между собой (каннибализация)?
Каннибализация возникает, когда несколько страниц оптимизированы под один и тот же ключ. При региональном продвижении это решается через чёткую структуру: каждая страница заточена под запрос с геомодификатором («услуга + город»), а не под общий федеральный ключ. Плюс — разные страницы должны отличаться не только городом, но и дополнительными ключами из семантического облака региона.
Сколько страниц безопасно публиковать в день?
Для новых сайтов — не более 5-10 страниц в день в первый месяц. Для сайтов с историей (от года, с хорошими поведенческими факторами) — до 20-30 страниц ежедневно без риска. Резкий прирост сотен страниц за несколько дней может вызвать ручную проверку со стороны Яндекса.
Что делать с ценами, если они разные в регионах?
Цены передаются в шаблон как переменные из Excel-таблицы или из вашей CRM. ТекстЗавод поддерживает импорт данных из структурированных таблиц — вы один раз заполняете файл с региональными параметрами, и при генерации каждая страница получает актуальные цифры. Модель не придумывает цены — она вставляет те, что вы передали в исходном материале.
Как проверить, что страница действительно уникальна, а не просто «перемешана»?
Формальная уникальность по шинглам — необходимое, но не достаточное условие. Проверяйте три вещи: уникальность по text.ru выше 85%, отсутствие флага AI-детекции, и — самое важное — смысловое различие страниц. Откройте две страницы для разных городов и прочитайте их подряд. Если ощущение «один и тот же текст с другим городом» — нужна дополнительная вариативность в промпте.
Нужен ли редактор, если платформа проверяет тексты автоматически?
Редактор нужен для выборочного контроля фактов и тональности. Алгоритм не знает, что ваш офис в Казани переехал, что акция закончилась или что в регионе принято обращаться по имени-отчеству. Хватает одного специалиста, который просматривает 10-15% страниц перед публикацией — это 2-3 часа работы на сотню материалов вместо 40+ часов при полностью ручном процессе.
Масштабирование контента для регионального продвижения — это строгий расчёт, а не творческий процесс. Правильная архитектура шаблонов, чередование LLM-моделей, региональная семантика и двойная проверка качества дают результат, который ручная работа команды копирайтеров воспроизвести за те же деньги и сроки не сможет.
Сгенерируй 25 региональных страниц за 15 минут — промокод Завод03 даёт три статьи в подарок для первого теста на реальном проекте.