Как обойти проблему ‘галлюцинаций’ ИИ и заставить нейросеть использовать реальные кейсы вашей компании вместо общих фраз
Чат GPT текст пишет быстро — это факт. Но без правильной подготовки вы получите набор общих советов, которые не отличают ваш блог от тысячи других. Решение — загрузить нейросети конкретную фактуру до начала генерации, а не после. Ниже разберём: почему нейросеть без контекста выдаёт «воду», как собрать лонгрид на 8 000 знаков по шагам и что реально происходит при работе с инструментами вроде ТекстЗавода.
Почему нейросеть пишет воду и как это исправить

Без загруженного контекста бренда любая модель — ChatGPT, Claude, Gemini — выдаёт усреднённый текст. Это не баг, это архитектура: модель предсказывает наиболее вероятные слова на основе обучающего корпуса, а не ваших данных.
Ситуация стандартная. Вы вводите запрос «напиши статью про контент-маркетинг для B2B». Нейросеть генерирует текст с клише уровня 2015 года: «контент — это король», «важно понимать потребности аудитории», «создавайте ценность для читателя». Три абзаца такого материала — и профильный читатель закрывает вкладку.
Корневая проблема — отсутствие информационной базы. Модель не знает, что вы продаёте, кому, какие кейсы у вас есть и чем ваш подход отличается от конкурентов. Она заполняет этот пробел шаблонами.
Три признака «пустого» текста
Их легко опознать ещё до публикации:
Штампы в первом абзаце. Фразы «в современном мире» или «важно отметить» — надёжный индикатор того, что модель работала без контекста. По данным поведенческих тестов, читатель принимает решение уйти или остаться в течение первых 15 секунд. Шаблонный зачин эту проверку не проходит.
Советы без цифр и примеров. «Публикуйте регулярно», «пишите для аудитории», «оптимизируйте под SEO» — это не экспертный контент. Это пересказ очевидного. Читатель, который уже работает в нише, такой текст игнорирует.
Отсутствие специфики бренда. Если убрать название компании из статьи и она останется универсальной — значит, нейросеть работала в вакууме. Такой материал не формирует доверие и не прогревает к покупке.
Как подать фактуру нейросети правильно
Решение — не в смене модели. ChatGPT, Claude и другие справятся с задачей, если получат структурированные данные заранее.
Что нужно загрузить перед генерацией:
Профиль компании. Чем занимаетесь, кто клиенты, какие результаты уже есть. Конкретные цифры: «сократили время на создание контента с 4 часов до 40 минут», «вывели 12 статей в топ-10 Яндекса за 3 месяца».
Кейсы и примеры. Реальные ситуации из практики. Не «мы помогаем клиентам», а «клиент из ниши юридических услуг получил 340 органических переходов за первый месяц после публикации трёх статей»
Семантическое окружение запроса. Какие вопросы реально задаёт ваша аудитория — это можно снять через Яндекс Wordstat или аналитику выдачи по целевым запросам.
Tone of Voice. Как вы говорите с клиентами: официально, по-партнёрски, с юмором или сухо и по делу. Без этого модель выберет нейтральный академический тон, который не совпадёт с вашим брендом.
В ТекстЗаводе для этого предусмотрен отдельный модуль «Профиль компании» — он загружается один раз и автоматически встраивается в каждую генерацию. Нейросеть получает бренд-контекст до того, как начинает писать, а не после.
| Без профиля компании | С профилем компании |
|---|---|
| «Контент-маркетинг помогает бизнесу расти» | «За 6 месяцев ведения блога клиент получил 2 400 органических переходов в месяц» |
| «Важно публиковать регулярно» | «График публикаций: 3 статьи в неделю — оптимальный темп для молодого проекта» |
| «Создавайте ценность для читателя» | «Разбор кейса: как один лонгрид на 7 000 знаков заменил 4 месяца рекламного бюджета» |
| «Оптимизируйте тексты под поисковики» | «Парсинг топ-30 по запросу показал: все конкуренты игнорируют раздел FAQ — это ваше окно» |
| Общие советы без цифр | Конкретные данные с привязкой к результату |
Галлюцинации — отдельная история. ChatGPT иногда придумывает несуществующие факты, исследования и цитаты. Это не злой умысел — модель достраивает «правдоподобное» продолжение, когда не хватает данных. Метод защиты: давать модели реальные цифры и просить опираться только на предоставленные данные, без «дополнений». Плюс обязательная фактчекинг-итерация перед публикацией.
Сборка лонгрида от плана до финальной вычитки
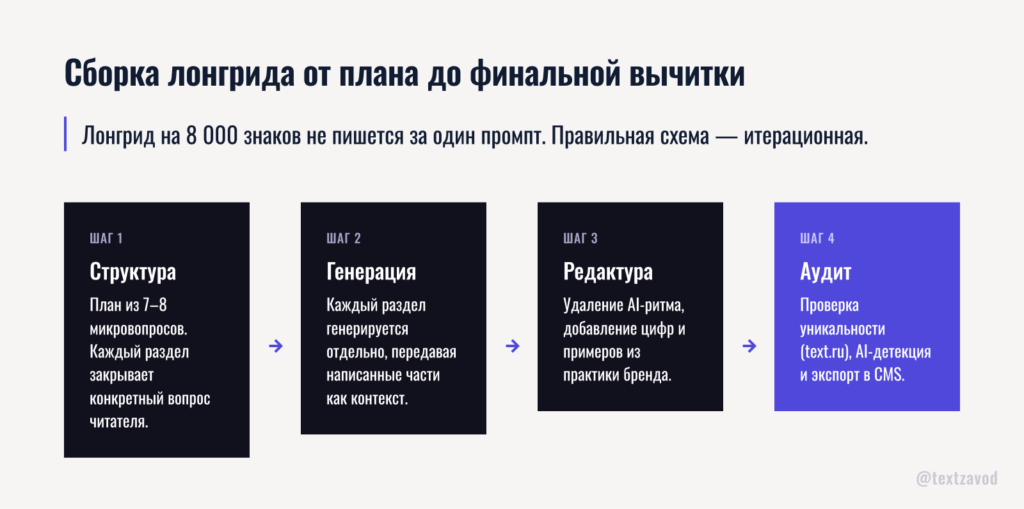
Лонгрид на 7–8 тысяч знаков не пишется за один промпт. Попытка получить всё сразу даёт рыхлый текст с повторами и провалами логики ближе к середине. Правильная схема — итерационная: сначала структура, потом каждый раздел отдельно.
Шаг 1. Структура из 7–8 разделов
Хороший план — не список тем, а список микровопросов. Каждый раздел закрывает один конкретный вопрос читателя.
Пример для статьи «Как привлекать клиентов через блог»:
- Почему блог работает лучше рекламы на длинной дистанции
- SEO-продвижение через контент: как статья в топе приводит клиентов месяцами
- GEO-оптимизация — продвижение в нейровыдаче Яндекса, Google AI Overview и ChatGPT
- Как определить темы, которые реально ищет ваша аудитория
- Структура статьи, которую дочитывают до конца
- Редактура нейротекста: что убрать, что добавить
- График публикаций: сколько статей нужно для видимого результата
- Частые ошибки и как их избежать
Каждый пункт — отдельный промпт. Это не дольше, а быстрее: короткий чёткий запрос даёт более плотный и управляемый результат, чем один гигантский.
Шаг 2. Генерация по частям
Это ключевой момент при создании материалов объёмом 15–20 тысяч знаков. Если запрашивать текст целиком, модель теряет нить между введением и финалом — особенно заметно в разделах с цифрами и примерами.
Схема работы:
- Генерируете введение с прямым ответом на главный вопрос статьи (первые 100 слов должны содержать основной ключ и давать конкретный ответ — это условие попадания в Featured Snippet и нейровыдачу).
- Каждый раздел генерируете отдельно, передавая модели план и уже написанные части как контекст.
- После каждого раздела проверяете логическую связку с предыдущим.
Джипити генерация текста по такой схеме занимает 15–20 минут на статью в 6 000 знаков. Это реальные цифры, а не маркетинговое обещание.
Шаг 3. Промпт с нужными параметрами
Структура промпта, которая работает:
Роль: SEO-копирайтер с опытом в [ниша]
Аудитория: [описание читателя — кто он, что знает, что хочет узнать]
Задача: написать раздел [название] для статьи [тема]
Тон: [деловой / партнёрский / разговорный]
Длина: [N знаков]
Запрещено: общие фразы без конкретики, пассивный залог, клише
Данные для использования: [конкретные цифры, кейсы, факты из профиля компании]
Чем детальнее бриф, тем плотнее текст. Исследование MIT и Stanford по применению генеративного ИИ в рабочих задачах зафиксировало: сотрудники с чётко сформулированными задачами выполняли письменные задания на 37% быстрее, чем те, кто работал с размытыми инструкциями. Это не про скорость печати — это про качество промпта.
Шаг 4. Редактура нейротекста
Chat GPT нейросеть текст пишет грамотно, но с характерными паттернами. Их нужно убрать перед публикацией.
Что убирать при редактуре нейротекста:
- Симметричные конструкции: «Во-первых… Во-вторых… В-третьих…» — это типичный AI-ритм, детекторы его распознают сразу.
- Деепричастные обороты в конце предложений, «надувающие» значимость: «…тем самым обеспечивая долгосрочный рост», «…демонстрируя экспертность бренда».
- Пассивный залог: «было проведено исследование», «является ключевым инструментом».
- Абзацы одинаковой длины — живой текст всегда ритмически неровный.
Что добавлять:
- Конкретные цифры вместо общих утверждений.
- Короткие предложения после длинных — создаёт ритмический контраст.
- Прямые обращения к читателю в моменты, когда нужно подтолкнуть к действию.
- Реальные примеры из практики — хотя бы один на раздел.

Шаг 5. Проверка через AI-детектор
Перед публикацией статья проходит через text.ru — и не только на уникальность, но и на AI-детекцию. В 2026 году это стандартная процедура для любого контент-проекта, который хочет оставаться в индексе.
Нормативы для прохождения фильтров:
| Параметр | Норма | Критическая зона |
|---|---|---|
| Уникальность (антиплагиат) | > 95% | < 85% — риск пессимизации |
| AI-вероятность (text.ru) | < 30% | > 60% — флаг для поисковика |
| Академическая тошнота | ≤ 9% | > 12% — переспам |
| Плотность основного ключа | 1–2% | > 3% — санкции |
| Общая плотность всех ключей | 3–4% | > 5% — риск |
В ТекстЗаводе эта проверка встроена в процесс — антиплагиат и AI-детекция через text.ru запускаются автоматически после генерации. Не нужно копировать текст в отдельный сервис и ждать результата.
Шаг 6. SEO-аудит и публикация
После редактуры — SEO-проверка по базовым параметрам: вхождение ключей, структура заголовков H1–H3, мета-тег description, внутренние ссылки. И только потом публикация.
Автоматический экспорт в WordPress экономит контент-менеджеру около 40 минут на каждой статье — это форматирование, вставка изображений, заполнение мета-полей. При графике 3–5 статей в день это 2–3 часа ежедневно, которые уходили на техническую рутину.
Кейс ТекстЗавода: как один тезис превратился в статью на 8 000 знаков

Разберём реальный сценарий работы на примере задачи из практики. Исходная точка — один тезис: «SEO-продвижение через контент дешевле рекламы на длинной дистанции».
Этап 1. Сбор данных из Wordstat и аналитики выдачи
Перед тем как писать, нужно понять, что именно ищут люди по этой теме. Парсинг через интеграцию с Яндекс Wordstat дал кластер из 47 запросов. Среди них — вопросы, которые конкуренты в топ-10 не закрывали вообще: «сколько стоит вести блог компании», «как долго ждать результата от SEO-статей», «что лучше — контекстная реклама или блог».
Это неучтённые области семантики — и они стали основой для структуры статьи.
SERP-анализ первых 30 позиций по основному запросу показал: 8 из 10 статей в топе не содержат конкретных цифр по срокам окупаемости контент-маркетинга. Значит, статья с реальными данными автоматически выделяется на фоне конкурентов.
Почему SEO-контент работает иначе, чем реклама
Статья в топе поисковика — это актив, а не расход. Реклама в Яндекс.Директе приводит трафик ровно пока идёт бюджет. Отключили кампанию — трафик упал до нуля в тот же день. Контент работает иначе.
Хорошо оптимизированная статья удерживает позиции месяцами и даже годами без дополнительных вложений. Человек сам нашёл материал через поиск, сам прочитал, сам убедился в экспертности — и приходит к покупке уже прогретым. Это принципиально другая механика, чем прерывающий баннер.
Отдельная история — GEO-оптимизация, то есть продвижение в нейровыдаче. Когда пользователь задаёт вопрос Яндекс Алисе, получает ответ в Google AI Overview или спрашивает ChatGPT — источником становится контент с сайтов, которые правильно структурированы под ответы нейросетей. Эта ниша в Рунете пока почти свободна. Занять место в нейровыдаче сейчас — значит зайти первым, пока конкуренты ещё не разобрались в механике.
Для попадания в нейроблоки нужны: прямые ответы на вопросы в первых предложениях после заголовка, FAQ-блоки, конкретные цифры и структурированные списки. Именно так устроены тексты, которые Яндекс Нейро и Google AI Overview цитируют в своих сводках.
ТекстЗавод анализирует первую страницу выдачи по целевым запросам, строит контент-план с учётом семантических пробелов конкурентов и генерирует тексты, оптимизированные одновременно под классическое SEO и под нейровыдачу. Попробуйте: промокод Завод03 даёт доступ к трём статьям без оплаты.
Этап 2. Генерация заголовков и выбор по методике 4U
Claude сгенерировал пять вариантов заголовков. Оценка шла по четырём критериям методики 4U: полезность (Useful), срочность (Urgent), уникальность (Unique), специфичность (Ultra-specific).
Результаты сравнения:
| Вариант заголовка | Useful | Urgent | Unique | Ultra-specific | Итог |
|---|---|---|---|---|---|
| «Контент-маркетинг для бизнеса» | ✓ | — | — | — | 1/4 |
| «Как вести блог компании» | ✓ | — | — | — | 1/4 |
| «SEO-блог vs реклама: что выгоднее» | ✓ | ✓ | ✓ | — | 3/4 |
| «Контент окупается за 4 месяца: расчёт для малого бизнеса» | ✓ | ✓ | ✓ | ✓ | 4/4 |
| «Как писать статьи для блога» | ✓ | — | — | — | 1/4 |
Победил четвёртый вариант — с конкретным сроком и указанием целевой аудитории. CTR у заголовков с цифрами стабильно выше, чем у общих формулировок. Это не теория — это аналитика выдачи по сотням ниш.

Этап 3. Структура и генерация по разделам
После выбора заголовка — план из восьми разделов. Каждый закрывает один конкретный вопрос: от «почему контент лучше рекламы» до «как измерить результат через 3 месяца».
Чат гпт сделать текст по каждому разделу занял в среднем 90 секунд. С учётом промпт-подготовки и передачи контекста — около 15 минут на всю статью в черновом варианте.
Ключевой момент: в каждый промпт передавались данные из профиля компании и реальные кейсы. Нейросеть не придумывала примеры — она структурировала предоставленные факты. Это и есть разница между «водой» и экспертным контентом.
Этап 4. Редактура и проверка
После генерации всех разделов — сборка в единый документ и редактура по чеклисту:
- Убрать симметричные конструкции и AI-ритм
- Добавить ритмический контраст (короткие предложения после длинных)
- Проверить фактуру: все цифры должны быть реальными или убраны
- Прогнать через text.ru: уникальность и AI-детекция
Финальный результат: статья 8 200 знаков, уникальность 97%, AI-вероятность по text.ru — 18%. Время от тезиса до публикации — 47 минут, включая редактуру.
Автоматическая публикация через модуль экспорта в WordPress закрыла последний этап без участия контент-менеджера. Форматирование, мета-теги, категории — всё выставилось автоматически.
Сгенерируй 25 таких статей за 15 минут — именно столько занимает пакетная генерация в ТекстЗаводе при заранее настроенном профиле компании. Промокод Завод03 открывает первые три материала бесплатно.
Частые вопросы о создании лонгридов через нейросеть

Можно ли полностью автоматизировать написание статей через ChatGPT без редактуры?
Технически — да. На практике — нет, если цель не просто заполнить сайт, а получить трафик и прогреть аудиторию. Нейросеть без редактуры оставляет AI-паттерны, которые text.ru и поисковые алгоритмы распознают. Плюс фактчекинг нельзя пропускать: модели иногда придумывают цифры и исследования, которых не существует. Минимальная редактура занимает 20–30 минут на статью в 6 000 знаков.
Как часто нужно обновлять профиль компании для нейросети?
Раз в квартал или при значимых изменениях: новые кейсы, изменение позиционирования, новые продукты. Актуальный профиль — это актуальная фактура в каждом тексте. Устаревшие данные модель использует так же охотно, как и свежие, не делая между ними различий.
Сколько знаков оптимально для SEO-статьи в 2025–2026 году?
Зависит от конкурентной среды в нише. Снимок выдачи Яндекса по большинству информационных запросов показывает: материалы в топ-3 содержат от 6 000 до 12 000 знаков. Для узких запросов с низкой конкуренцией достаточно 4 000–5 000. Для широких коммерческих — 8 000–15 000. Ориентируйтесь на среднюю длину топ-5 конкурентов по вашему запросу, а не на общие рекомендации.
Что такое GEO-оптимизация и зачем она нужна прямо сейчас?
GEO (Generative Engine Optimization) — адаптация контента под нейровыдачу: ответы Яндекс Алисы, Google AI Overview, ChatGPT. Когда пользователь задаёт вопрос нейросети, та цитирует источники. Правильно структурированная статья с прямыми ответами, FAQ-блоками и конкретными данными попадает в эти цитаты. В Рунете эта ниша пока малоконкурентна — у большинства блогов контент не адаптирован под нейровыдачу вообще.
Как проверить, что нейросеть не придумала факты в статье?
Проверяйте каждую цифру и каждую ссылку на исследование вручную. Если модель называет «исследование X показало Y%» — ищите первоисточник. Не нашли за 2 минуты — убирайте из текста. Безопаснее давать модели реальные данные в промпте и явно запрещать добавлять внешние факты без вашего подтверждения.
Как подобрать ключевые слова для лонгрида, если нет SEO-специалиста?
Яндекс Wordstat + ручной просмотр топ-10 по основному запросу. В Wordstat смотрите «похожие запросы» и «запросы с этим словом» — это и есть ваша семантика. В топ-10 изучайте заголовки H2–H3 у конкурентов: они показывают, какие подтемы поисковик считает релевантными. Плюс блок «Люди также спрашивают» в Google — готовые вопросы для FAQ-раздела.
Что даёт модуль «Профиль компании» в ТекстЗаводе по сравнению с ручным промптом?
Загружается один раз и автоматически встраивается в каждую генерацию — не нужно каждый раз прописывать контекст бренда заново. Модуль структурирует данные в формате, который Claude и Gemini воспринимают как приоритетный источник. Это снижает вероятность галлюцинаций и повышает долю фирменной конкретики в тексте. При пакетной генерации 25 статей экономия на промпт-подготовке — около 3 часов.
Создайте свой первый экспертный лонгрид в ТекстЗаводе бесплатно — промокод Завод03 действует при регистрации на textzavod.ru.