Разбираем механику SERP-анализа: почему обычный промпт проигрывает парсингу реальных конкурентов и как ТекстЗавод автоматизирует этот процесс
Попросить нейросеть написать текст онлайн — и получить статью, которая реально ранжируется, это две разные задачи. Первая занимает минуту. Вторая требует понимания того, что именно Яндекс показывает в первой тридцатке по вашему запросу прямо сейчас. Без этого понимания любой промпт — стрельба вслепую.
В этой статье разберем три вещи: почему слепая генерация не попадает в топ, как работает механика парсинга выдачи и какие параметры промпта превращают сырой ИИ-черновик в материал, который проходит фильтры Яндекса.
Слепая генерация против анализа конкурентов

Большинство SEO-специалистов уже умеют написать текст через ИИ. Проблема не в умении — в результате. Статьи, созданные без опоры на актуальную выдачу, попадают в топ значительно реже тех, что написаны с учетом реальной структуры конкурентов.
Почему обычный GPT не видит текущую выдачу
Языковая модель без доступа к интернету работает на обучающей выборке с датой среза. ChatGPT 4o обучен на данных до начала 2024 года. Claude 3.5 — аналогично. Это значит: модель не знает, какие статьи сейчас стоят в топе по вашему запросу, какие заголовки используют лидеры ниши, какой объем считается нормой для данной темы в 2026 году.
Модель галлюцинирует структуру. Она выдает то, что статистически встречалось в похожих текстах из обучающей выборки. Это не плохой черновик — это черновик под выдачу двухлетней давности.
Поисковый интент меняется. Запрос «купить кондиционер» в 2024 году мог тянуть коммерческий стек с карточками товаров, а в 2026-м — информационные лонгриды с разбором характеристик. Модель про это не знает. И текст, который она пишет, может не совпадать с тем, что Яндекс ожидает увидеть на этой позиции.
Разрыв между «просто текстом» и статьей из ТОП-10
Анализ первой десятки по большинству коммерческих и информационных запросов показывает устойчивую закономерность: лидеры используют от 15 до 20 специфических LSI-фраз, которых нет в «общем» тексте на ту же тему. Это не просто синонимы. Это термины, которые сигнализируют Яндексу о глубине охвата.
Пример из практики: по запросу «утепление фасада пенополистиролом» в топе стоят статьи, которые упоминают «точку росы», «паропроницаемость», «адгезию клея» и «армирующую сетку». Нейросеть без контекста конкурентов пишет про «тепло и уют». Разница в семантическом облаке — принципиальная.
Второй разрыв — объем. Если в топе лонгриды по 12 000–15 000 знаков, текст на 3 000 знаков не будет ранжироваться при прочих равных. Это не теория — это сигнал о глубине раскрытия темы, который Яндекс учитывает при ранжировании.
Блок «Люди также ищут» как обязательный чек-лист
Яндекс в 2025–2026 году усилил вес дополнительных вопросов из блока «Люди также ищут». Алгоритм смотрит: закрывает ли статья смежные интенты или только прямой запрос. Статьи, которые охватывают 5–7 смежных вопросов из этого блока, получают преимущество при прочих равных факторах.
Генерировать текст с помощью GPT без предварительного снятия этих вопросов — значит заведомо пропускать часть структуры, которую Яндекс считает обязательной для полного ответа на запрос.
| Подход к генерации | Покрытие интентов | Риск потери позиций |
|---|---|---|
| Промпт без SERP-данных | 30–50% от нужных тем | Высокий |
| Промпт + ручной анализ ТОП-5 | 60–70% | Средний |
| Автоматический парсинг ТОП-30 | 85–95% | Низкий |
| Парсинг + блок «Люди также ищут» | 90–98% | Минимальный |
Ручной анализ пяти конкурентов занимает у опытного SEO-специалиста от 40 минут до 2 часов. Тридцать позиций вручную — нереалистично. Именно здесь автоматизация меняет экономику процесса.
Как ТекстЗавод парсит ТОП-30 за 60 секунд

Механика простая, но за ней стоит несколько нетривиальных решений. Разберем по слоям: что именно собирается, как это превращается в ТЗ и почему результат отличается от ручной работы.
Что модуль SERP-анализа собирает у конкурентов
SERP-анализ в ТекстЗаводе выкачивает данные по всем тридцати позициям выдачи Яндекса по целевому запросу. Не по пяти, не по десяти — по тридцати. Это важно, потому что ниши 6–30 часто содержат структурные решения, которых нет у лидеров первой пятерки.
По каждой странице собирается:
- Иерархия заголовков H1–H3 — полная структура, а не только верхний уровень. Это дает картину того, какие подтемы конкуренты считают обязательными.
- Объем текста в знаках — с учетом разброса. Если в топе медиана 11 000 знаков, а один конкурент занимает 3-е место с 18 000 — это сигнал о нише, где глубина ценится выше краткости.
- LSI-фразы и тематические кластеры — термины, которые встречаются у 60%+ конкурентов и не входят в прямой ключ. Именно они формируют семантическое облако, без которого текст выглядит неполным.
- Плотность главного ключа у каждого конкурента — чтобы не выйти за норму ниши. В одних тематиках Яндекс спокойно принимает 2,5%, в других 1,8% уже на грани.
Весь этот сбор данных занимает 45–60 секунд. Вручную та же работа — минимум 3–4 часа при честном подходе.

Средний объем как критический маркер ниши
Объем статьи — это не про «больше текста = лучше». Это про соответствие запросу. Яндекс обучен на корреляциях: для каких запросов пользователь дочитывает короткий ответ, а для каких прокручивает лонгрид до конца.
ТекстЗавод считает медианный объем по ТОП-30 и выставляет целевой диапазон для генерируемой статьи. Если медиана 14 000 знаков, система не позволит сгенерировать текст на 4 000 — это прямой путь к пессимизации.
Практический пример: по запросам в тематике «бухгалтерские услуги для ИП» медианный объем в топе Яндекса в 2025 году составляет около 8 000–10 000 знаков. По запросам «как выбрать ноутбук» — уже 15 000–18 000. Разница двукратная. Без парсинга эту норму угадать невозможно.
Как платформа выделяет тематические кластеры для ТЗ
После сбора заголовков H1–H3 у тридцати конкурентов система кластеризует темы по частоте упоминания. Кластер с частотой 70%+ становится обязательным разделом ТЗ. Кластер с частотой 30–70% — рекомендованным. Ниже 30% — опциональным.
Это и есть та самая доказательная база для нейросети. Не «напиши про X» — а «напиши про X, включая обязательно разделы A, B, C и желательно D, E». Разница в качестве результата — принципиальная.
Структура ТЗ, которую формирует ТекстЗавод после парсинга:
- Целевой объем в знаках (диапазон на основе медианы ТОП-30).
- Обязательные H2-разделы (встречаются у 70%+ конкурентов).
- Рекомендованные H3-подразделы (встречаются у 40–69%).
- Список LSI-фраз для включения в текст (минимум 12–15 штук).
- Целевая плотность главного ключа (на основе среднего по ТОП-10).
- Смежные вопросы из блока «Люди также ищут» — для закрытия дополнительных интентов.
Такое ТЗ копирайтер получает за 15 минут. Раньше на его составление уходило 4 часа. Это не преувеличение — это фактические трудозатраты при ручном подходе.
Интеграция с Яндекс Wordstat
Параллельно с парсингом выдачи платформа обращается к Wordstat. Это нужно для двух вещей: проверки частотности дополнительных ключей и выявления сезонных пиков в нише.
Статья, написанная без учета частотности вспомогательных ключей, может упустить кластеры с суммарным трафиком в несколько раз больше главного запроса. Wordstat показывает, какие смежные фразы реально ищут — и они автоматически попадают в ТЗ.
SEO-продвижение через контент и почему это работает дольше рекламы
Статья в топе Яндекса по целевому запросу работает месяцами — без дополнительных расходов после публикации. Реклама в Яндекс.Директе устроена иначе: трафик идет ровно пока идет бюджет. Остановил кампанию — остановился поток.
SEO-статья прогревает читателя иначе. Человек сам нашел материал по своему запросу, сам изучил, сам убедился в экспертности автора — и приходит с запросом уже готовым к диалогу, а не прерванным рекламным баннером в неподходящий момент. Это качественно другая аудитория с другой конверсией.
Отдельный канал — GEO-оптимизация, то есть попадание в нейровыдачу Яндекс Алисы, Google AI Overview и аналогичные блоки ChatGPT. Алгоритмы этих систем цитируют структурированные статьи с четкими ответами на конкретные вопросы. Ниша пока практически свободна: большинство сайтов не оптимизированы под формат нейроответов, и зайти в нее сейчас — значит занять позицию до того, как туда придут конкуренты.
ТекстЗавод при генерации учитывает оба канала: анализирует структуру топа, строит контент-план под реальные запросы и выдает готовые тексты, оптимизированные и под классическую выдачу, и под нейроблоки. Это те самые статьи, которые автоматически приводят прогретых читателей — без дополнительных вложений после публикации.
Настройка промпта на основе собранной фактуры
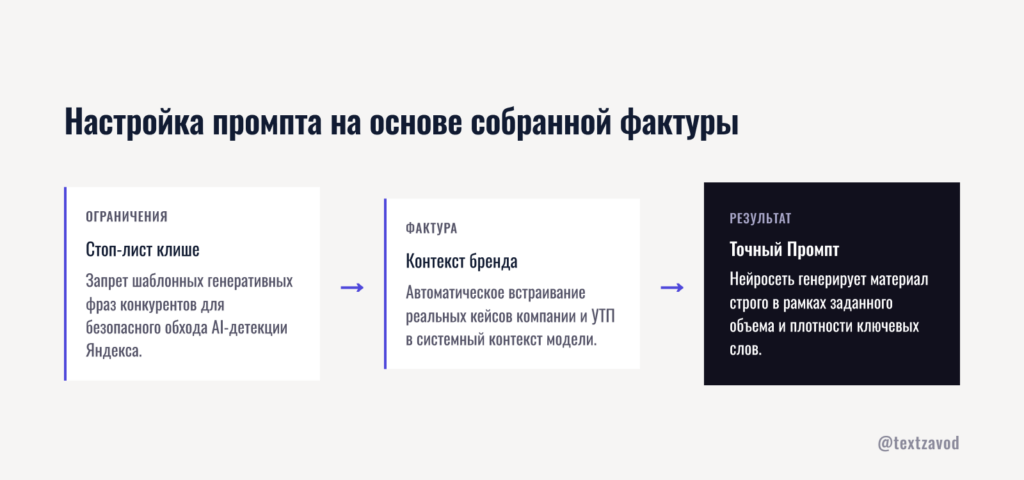
Парсинг выдачи дает сырье. Качество финального текста определяется тем, как это сырье упаковано в промпт для нейросети. Здесь большинство SEO-специалистов теряют половину потенциала — передают модели список ключей и заголовков, но не дают ей контекст, который отличает хороший текст от среднего.
Как передать нейросети «запрещенные штампы» конкурентов
Анализ ТОП-30 дает не только то, что нужно включить, но и то, чего лучше избежать. Если восемь из десяти конкурентов начинают статью с «В современном мире автоматизация…» — именно эту фразу Яндекс видел тысячи раз. Она не несет сигнала экспертности.
ТекстЗавод при анализе конкурентов выделяет повторяющиеся генеративные клише — фразы, которые встречаются у большинства текстов в топе и с высокой вероятностью сгенерированы другими ИИ-инструментами. Эти фразы передаются в промпт как явный стоп-лист.
Пример: для тематики «CRM-системы для малого бизнеса» стоп-лист может включать «оптимизация бизнес-процессов», «повышение эффективности», «комплексное решение». Модель, получив этот список, автоматически ищет другие формулировки — и результат проходит AI-детекцию заметно лучше.
Это снижает вероятность попадания под фильтр Яндекса за машинный контент. Не исключает полностью — но снижает риск детекции.
Контекст бренда как инструмент дифференциации
Чистая SEO-статья без брендовой составляющей — это commodity. Её можно найти на десятке сайтов. Статья с конкретным опытом компании, упоминанием реальных кейсов и фирменной терминологией — уже уникальный ресурс.
ТекстЗавод позволяет загрузить профиль компании: описание продукта, ключевые тезисы, фирменный стиль изложения, примеры формулировок. Эти данные встраиваются в промпт на уровне системного контекста — до того, как модель начинает писать.
Результат: информационная статья про «выбор CRM» содержит конкретную отсылку к опыту клиентов компании, не выглядит рекламной вставкой и при этом органично упоминает продукт в нужном месте. Поисковый интент закрыт, УТП бренда присутствует — оба условия выполнены.
Плотность ключевых слов и фильтр «Баден-Баден»
Фильтр «Баден-Баден» Яндекса работает с 2017 года и регулярно обновляется. Его логика: если ключевые слова встречаются неестественно часто или явно вставлены без смысловой связи — страница получает понижение в выдаче.
Критический порог — плотность главного ключа выше 2,5% по данным Wordstat для большинства ниш. Но это не жесткое правило: в некоторых тематиках нормой является 1,8%, в других — до 3%. Именно поэтому ориентироваться нужно на медиану по ТОП-10, а не на общую рекомендацию.
Что контролирует ТекстЗавод по ключевым словам:
- Плотность главного запроса в тексте — строго в диапазоне, характерном для ТОП-10 ниши.
- Суммарная частотность всех ключей — не выходит за 3,5–4% от общего объема.
- Распределение LSI-фраз — равномерно по разделам, без кластеризации в одном абзаце.
- Первое вхождение главного ключа — в первых 100 словах, естественно.
После генерации текст проходит двойную проверку: антиплагиат через text.ru и прогон через AI-детектор. Если показатели выходят за целевые значения — система флагирует конкретные фрагменты для доработки. Не весь текст, а именно проблемные места.

Настройка объема и форматирования под нишу
Промпт без указания целевого объема дает текст произвольной длины. Модель сама решает, когда она «достаточно раскрыла тему». Это решение часто не совпадает с тем, что нужно для ранжирования.
ТекстЗавод передает в промпт конкретный диапазон знаков — на основе медианы ТОП-30. Плюс структуру: какие H2-разделы обязательны, какие рекомендованы, сколько знаков отвести на каждый раздел. Модель работает не как свободный автор, а как исполнитель четкого технического задания.
Именно этот подход позволяет за 15 минут сгенерировать 25 статей, каждая из которых соответствует требованиям конкретной ниши — а не усредненному представлению модели о «хорошей статье».
| Параметр промпта | Без SERP-данных | С данными ТОП-30 |
|---|---|---|
| Объем текста | Произвольный (3–8 тыс. знаков) | Целевой диапазон ниши |
| Структура H2/H3 | Модель придумывает сама | На основе частоты у конкурентов |
| LSI-фразы | Случайные | 12–15 обязательных из парсинга |
| Плотность ключа | Неконтролируемая | Медиана ТОП-10 ниши |
| Стоп-список | Отсутствует | Клише из анализа конкурентов |
| Проверка качества | Нет | Антиплагиат + AI-детекция |
Разница в конверсии этих двух подходов в позиции топа — предмет отдельного исследования. Noy и Zhang в 2023 году показали, что ИИ-инструменты дают максимальный выигрыш именно в структурных и аналитических задачах — черновик, выжимка тезисов, составление ТЗ — а не в написании финального текста с нуля. SERP-анализ как раз и решает структурную задачу: дает модели готовый каркас вместо чистого листа.
Часто задаваемые вопросы

Можно ли написать текст нейросетью онлайн без парсинга выдачи и попасть в топ?
Технически — да, но вероятность ниже. Без данных о структуре конкурентов модель не знает, какие подтемы обязательны для полного закрытия интента. Статья может быть грамотной и полезной, но не охватывать 30–40% тем, которые Яндекс ожидает увидеть в топовом материале. Результат — позиции 15–30 вместо первой десятки.
Как часто нужно обновлять SERP-анализ для одной темы?
Для конкурентных ниш — раз в 3–4 месяца. Выдача меняется: появляются новые лидеры, меняется медианный объем, обновляются LSI-фразы. Если статья опубликована год назад и теряет позиции — первое, что стоит сделать, это повторный снимок выдачи и сравнение с текущей структурой.
Нейросеть написать текст и сгенерировать ТЗ — это одно и то же?
Нет. Генерация ТЗ — это аналитическая задача: собрать данные конкурентов, выделить обязательные темы, задать параметры объема и ключей. Написание финального текста — творческая задача с жесткими ограничениями. ТекстЗавод выполняет обе последовательно: сначала ТЗ на основе парсинга, затем генерация по этому ТЗ.
Что такое парсинг выдачи и зачем он нужен для контента?
Парсинг выдачи — автоматический сбор данных о страницах, которые Яндекс показывает в топе по конкретному запросу. Для контента это дает понимание структуры успешных статей: какие разделы включают лидеры, какой объем они публикуют, какие LSI-фразы используют. Без этих данных промпт для нейросети строится на предположениях, а не на фактах.
Как ИИ чат написать текст использует данные о бренде?
При наличии загруженного профиля компании модель получает системный контекст до начала генерации. Это означает, что фирменная терминология, ключевые тезисы и стиль изложения встраиваются в текст органично — не как рекламная вставка в конце, а как естественная часть экспертного материала. Читатель видит компетентность, а не рекламу.
Фильтр «Баден-Баден» — как понять, что статья под него попала?
Основной признак — резкое падение позиций страницы без изменения внешних факторов. Яндекс.Вебмастер в разделе «Безопасность и нарушения» фиксирует предупреждения, если фильтр применен явно. Но чаще статья просто не поднимается выше 20–30 позиции при хорошем ссылочном профиле — это косвенный сигнал о проблеме с качеством текста или переоптимизацией ключей.
Стоит ли использовать одну модель или комбинировать Claude и Gemini?
Для SEO-контента в Рунете оба варианта работают. Claude показывает более естественный русский язык и лучше держит заданный стиль на длинных текстах. Gemini сильнее в структурировании и работе с большими объемами данных. ТекстЗавод использует обе модели в зависимости от типа задачи — это и есть практическое применение комбинированного подхода без ручного переключения между сервисами.
Итог
Разрыв между «написать текст нейросетью онлайн» и «получить статью в топ-10 Яндекса» — это разрыв между слепой генерацией и работой с реальными данными выдачи. Парсинг ТОП-30, кластеризация тем по частоте у конкурентов, контроль плотности ключей и двойная проверка качества — это не опции, а обязательные шаги для контента, который реально ранжируется.
ТекстЗавод автоматизирует весь этот цикл: от снимка выдачи до готового текста с проверенными метриками. Не как замена экспертизы — как инструмент, который убирает механические действия и оставляет специалисту только стратегические решения.
Попробуйте ТекстЗавод прямо сейчас на textzavod.ru. Промокод Завод03 открывает три статьи бесплатно — проверьте на реальном запросе из вашей ниши.